When I was a kid, I loved looking up easter eggs in the software and games I used regularly. It was so fun finding these messages hidden by the developers, or to have a silly little game available in some boring spreadsheet program.
One “easter egg” which was more puzzling was in Windows Notepad. Under Windows XP, typing the sentence “bush hid the facts” in an empty Notepad window, saving it somewhere and the re-opening it would only show you garbled characters, either empty boxes or Chinese characters which translated to gibberish. This of course led to people theorizing about political conspiracies (link taken from Wikipedia).
Looking up this “feature” more recently, I discovered that it did not work in more recent versions of Windows: the sentence is displayed correctly upon re-opening. My research led me to Wikipedia, which has an entire article about this bug: according to sources from inside Microsoft, this was a misprediction from the Windows API function dedicated to guessing the encoding of a piece of text. It thought the text was written in UTF-16, when it should have guessed ASCII. You can play with text encodings in this small Javascript web app, although you might spoil yourself the end of the article if you do.
I decided to investigate for myself to better understand how this bug triggered.
What’s text encoding?
Like everything else on a computer, “plain text” is simply a way of interpreting strings of bytes as something else (I recommend watching the presentation Plain Text by Dylan Beattie to get an overview of the different text encoding standards and their evolution).
A “text encoding” represents rules to convert text (most of the time a succession of letters) into bytes, and to do the reverse operation (called “decoding”). Nowadays, most of the world has settled on Unicode to translate text to a succession of numbers (“code points”), and UTF-8 to convert this succession of numbers to a succession of bytes.
However, lots of different text encodings exist. Especially during the Windows XP days, you could not simply assume that any document you opened would be UTF-8-encoded Unicode: you had to either ask the user, or try to guess it yourself. Most of the time, your document could be in the following encodings:
- ASCII, which is a 7-bit encoding, able to encode 128 different characters. Good for English, but not for much else.
- Extended ASCII, which uses the 8th bit of ASCII to encode 128 more characters. However, which characters are available depend on which code page you have loaded. The code page determines which characters the upper 128 values correspond to. In English-speaking Europe, we mostly used code page 850, or Latin-1. Western-Europe latin languages had Latin-9, or CP 859.
- UTF-8 Unicode, where each character is encoded over 1 to 4 bytes. It has the nice property of being a superset of ASCII.
- UTF-16 Unicode, where each character is encoded over 2 bytes (most of the time). Because 2-byte words can be read in two different ways depending on your endianness, it is actually two different encodings: UTF-16-LE (Little Endian), and UTF-16-BE (Big Endian).
How do you actually determine the encoding of a text file? There’s no hard and fast rule, but you can do some educated guesses:
- If your text contains null bytes (
0x00), you can rule out ASCII and UTF-8: these encodings never write null bytes because they are usually used to signal the end of a string in C. - If your text starts with the magic number
0xFF 0xFE, also known as the Byte Order Mark, then it is probably UTF-16 Little Endian - Likewise, if it is
0xFE 0xFF, the it’s probably UTF-16 Big Endian. - In rare cases, UTF-8 text can start with
0xEF 0xBB 0xBF(I’ve never seen it though)
In all other cases, you have to decide on an encoding yourself. Let’s see how Notepad does it.
NOTEPAD.EXE
Determined to get to the bottom of it, I got a copy of Notepad from a Windows XP copy I had lying around, opened it up in IDA Free and started poking around (IDA Free now has a cloud decompiler!). Thankfully, the PDB for this version of Notepad can be freely grabbed from Microsoft’s servers, which gives us most of the function and variable names, greatly easing the reverse engineering.
The Wikipedia article mentioned before tells us that the “bug” comes from the advapi32!IsTextUnicode() function. Let’s see where Notepad uses it.
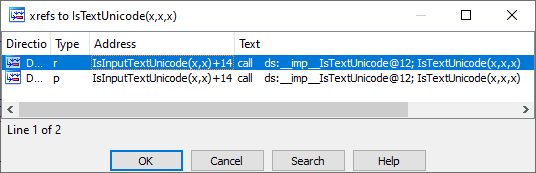
It appears that IsInputTextUnicode() is simply a wrapper around the previous function. It is itself used by two other functions:
fDetermineFileTypeLoadFile
The first one looks promising, let’s decompile it.
The function is pretty straightforward: it checks for an easy way out by looking at the buffer length (if it’s 0 or 1, it can’t be UTF-16), and then looks for a BOM at the beginning. If it doesn’t find any, then it relies on IsTextUnicode() to determine if the file is UTF-16-LE encoded.
Our quest continues! Let’s have a look at IsTextUnicode in advapi32.dll.
advapi32.dll
Well, that’s easy: IsTextUnicode is just a wrapper to ntdll!RtlIsTextUnicode.
Trying out the bug by hand
Before reversing the actual function, I decided to make sure that it was the culprit. So, I grabbed a copy of Visual C++ Express 2008 (ooooh, the memories) and tried implementing the smallest possible version of the bug.
It does look like there’s a problem! The problematic string is indeed identified as “Unicode” by the IsTextUnicode function. 0x2 means IS_TEXT_UNICODE_STATISTICS, or “The text is probably Unicode, with the determination made by applying statistical analysis. Absolute certainty is not guaranteed.” (MSDN)
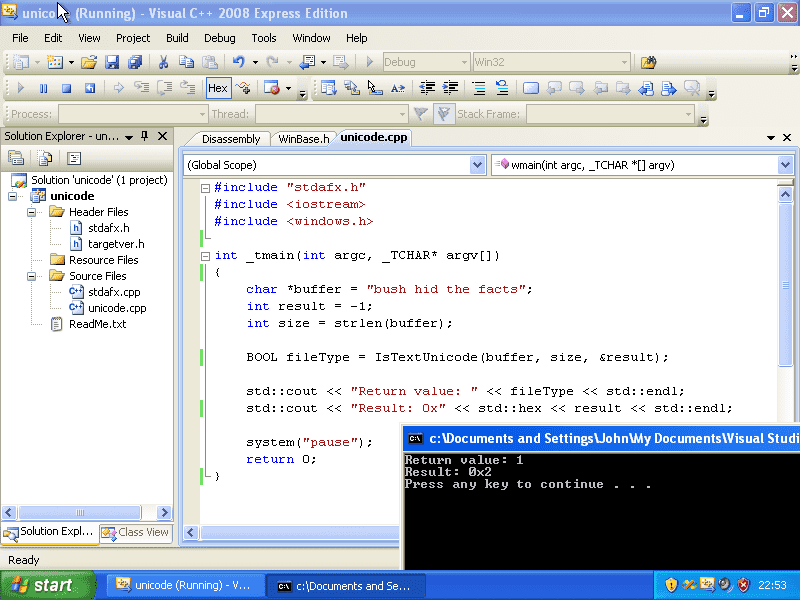
If you’re trying it out yourself, don’t forget to initialize the result variable to -1 to ask the function to run all tests. I lost an evening on that (who the hell invented “in and out” parameters?!).
This bug is still present in current versions of Windows! The same code produces the same (incorrect) result, but Notepad was updated to not rely on it as much (we’ll see what happened at the end of the post).
ntdll.dll
We’re now getting to the real stuff: the actual algorithm for IsTextUnicode. I’m not going to dump the entire function here, I’m instead going to explain the various interesting parts.
According to MSDN, the function is supposed to apply various heuristics to the buffer in order to determine whether the text could be Unicode or not. Some of them look innocent enough: it appears to be checking for the BOM, for control characters such as line returns or spaces, and at the length of the buffer.
One particular constant is interesting: it’s the one we already saw when we tried out the bug ourselves: IS_TEXT_UNICODE_STATISTICS. I’m interested to know what those “statistics” are.
The statistical tests assume certain amounts of variation between low and high bytes in a string
Let’s dive in!
The code will first check the size of the buffer: if it’s less than 2, it cannot possibly contain UTF-16, so we get a IS_TEXT_UNICODE_BUFFER_TOO_SMALL and an early return.
Then, the function checks for various UTF-16 control characters: space, tab, line and carriage return. If it finds any, it increments a variable. The same is done for Big Endian UTF-16. This will be used at the end of the algorigthm to set the IS_TEXT_UNICODE_CONTROLS and IS_TEXT_UNICODE_REVERSE_CONTROLS flags.
Certain characters also get special treatment: 0xFFFF, 0xFEFF (a BOM in the middle of the file), 0x0000 (16-bit null value), or 0x0A0D (a CRLF, but packed in one word). Any of these will get you a IS_TEXT_UNICODE_ILLEGAL_CHARS.
Finally, we get to the “statistics” part. The algorithm will compute the total variation between consecutive high bytes of each WORD in the buffer. It will do the same for consecutive low bytes.
The basic algorithm is as follows: for each word (16-bit integer) in the buffer, the high and low bytes are extracted. For each of them, the difference with the previous byte is computed, and added to a total.
Basically, for each uint16, composed of hi and lo bytes (0xHILO, encoded 0xLO 0xHI):
- variation_hi += abs( hi - prev_hi )
- variation_lo += abs( lo - prev_lo )
After going through at most 128 words (256 bytes), the two totals are compared:
- If there is at least three times more variation of the high byte than the low byte, then the buffer is assumed to contain UTF-16-LE-encoded text.
- On the other hand, if the low byte has a variation at least three times superior, then the function identifies the text as UTF-16-BE.
Here’s an example with the phrase hello world!:
| h | e | l | l | o | w | o | r | l | d | ! | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 68 | 65 | 6C | 6C | 6F | 20 | 77 | 6F | 72 | 6C | 64 | 21 |
- variation_hi = 0x65 + abs(0x65-0x6C) + abs(0x6C-0x20) + abs(0x20-0x6F) + abs(0x6F-0x6C) + abs(0x6C-0x21) = 341
- variation_lo = 0x68 + abs(0x68-0x6C) + abs(0x6C-0x6F) + abs(0x6F-0x77) + abs(0x77-0x72) + abs(0x72-0x64) = 138
Neither one is three times bigger than the other, so IsTextUnicode() doesn’t get fooled: the result is a resounding false! Although, as you can see, we’re not that far off: lowercase letters are located towards the end of the ASCII table, while punctuation and whitespace are in the first half. This means that a lowercase letter situated two characters after a special character is going to net a relatively big variation. Put too many of them one after the other, and you might go over the threshold.
Now, let’s run the algorithm with our old pal, bush hid the facts:
| b | u | s | h | h | i | d | t | h | e | f | a | c | t | s | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 62 | 75 | 73 | 68 | 20 | 68 | 69 | 64 | 20 | 74 | 68 | 65 | 20 | 66 | 61 | 63 | 74 | 73 |
- variation_lo = 0x62 + abs(0x62-0x73) + abs(0x73-0x20) + abs(0x20-0x69) + abs(0x69-0x20) + abs(0x20-0x68) + abs(0x68-0x20) + abs(0x20-0x61) + abs(0x61-0x74) = 572
- variation_hi = 0x75 + abs(0x75-0x68) + abs(0x68-0x68) + abs(0x68-0x64) + abs(0x64-0x74) + abs(0x74-0x65) + abs(0x65-0x66) + abs(0x66-0x63) + abs(0x63-0x73) = 185
In this case, we can see the threshold is indeed crossed, with a ratio of 3.09.It seems to be a combination of two things:
- “Space” characters fall exclusively on low bytes, meaning we get a pretty big difference every time. This difference is doubled, as the bytes before and after the space are lowercase characters.
- High bytes are pretty close in value to each other, which gives a relatively small difference every time.
None of the other heuristics match anything, which is why we only got a result of 2 in our test: only the statistics believe this is Unicode, but it’s enough for the function to return true.
The final part is getting all these sources mixed together. Depending on what was found, a boolean equation is used to determine if yes or no, the text is Unicode. For example, if illegal UTF-16 characters were found, then no amount of statistics will help: the function will return false!
Having fun with encodings
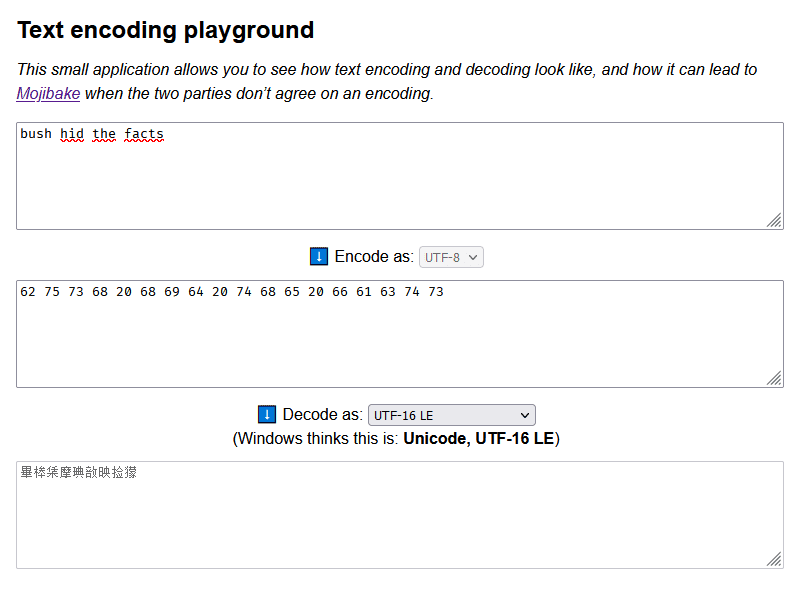
Alright! Now that we understand how this function works, why not reimplement it in Javascript to make a fun little toy? I’m not 100% sure it’s exactly the same, but the results it gives out are close enough to reproduce the bug :D
Here it is, available at /text-encoding. Meet me there!

If you try bush hid the facts, you will see that my reimplementation does indeed think that this is UTF-16-LE-encoded Unicode!
Alright, cool! Now let’s dive into a recent notepad.exe to see how they fixed the bug.
Reversing the Windows 10 notepad.exe
I’m going to go quick here: the fix is pretty funny. I can’t find any function named fDetermineFileType or IsInputTextUnicode, so let’s check out the cross-references to IsTextUnicode once again.
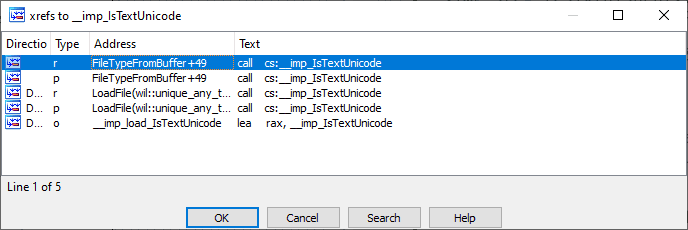
LMAO. They still use IsTextUnicode(), but don’t trust its output in the exact case of the bug: if its only source of truth is the statistics algorithm (IS_TEXT_UNICODE_STATISTICS = 2), and it didn’t have enough data to be sure, then it discards the result.
This indeed fixes this bug, but we can still instigate a bad prediction: we just have to make sure our file is bigger than 100 bytes, while still keeping the variation difference high enough.
There’s a simple way: let’s add a bunch of spaces before the sentence. Space (0x20) is the smallest printable character (actually, that’s TAB, but it would look bad), so it won’t affect the initial value of the variations too much.
>>> " "*100 + "bush hid the facts" # Scroll right
' bush hid the facts'
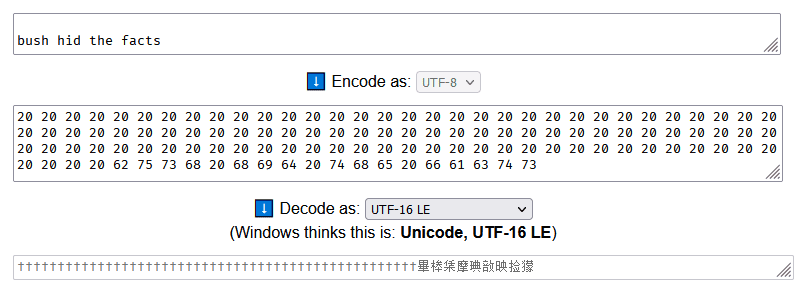
Let’s paste this ASCII string into an empty Notepad document, save it, and…
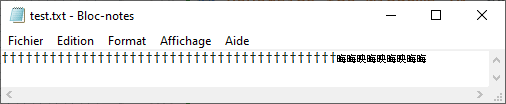
And we’re done here! I hope you enjoyed reading this post at least half as much as I enjoyed writing it.